반응형
7.1 토픽
- 사용자 작업 이벤트를 카프카 클러스터로 보내는 웹 기반 애플리케이션을 사용해 교육 수업을 위한 자리를 판매한다고 가정해보자.
- 위치에 대한 초기 검색 이벤트, 고객이 선택한 특정 교육에 대한 이벤트, 확인된 클래스에 대한 세 번째 이벤트가 있을 수 있다.
- 이벤트를 생성하는 애플리케이션이 모든 데이터를 단일 토픽으로 보내야 할까? 아니면 여러 토픽으로 나눠 보내야 할까?
- 각 메시지는 특정 유형의 이벤트인가? 각각 다른 토픽으로 분리되어 있어야 하는가 ?
- 토픽 설계는 2단계 프로세스로 본다.
- 첫번재는 우리가 가진 이벤트를 본다. 하나의 토픽에 속해 있는가 ? 둘 이상에 속해 있는가?
- 두번째는 각 토픽을 고려한다. 사용해야 하는 파티션의 수는 얼마인가?
- 가장 중요한 점은 파티션이 토픽별 설계에 대한 질문이지 클러스터 전체의 제한이나 요구가 아니라는 것이다.
- 토픽 생성을 위한 기본 파티션 수를 설정할 수 있지만, 대부분의 경우 토픽이 사용되는 방식과 보유할 데이터를 고려해야 한다.
- 일반적으로 고려해야 할 항목은 다음 3가지이다.
- 데이터 정확성
- 순서를 지정해야 하는 이벤트가 동일한 토픽에 있어야 한다
- 타임스탬프를 기반으로 이벤트를 배치할 수 있다 ▶ 교차 토픽 이벤트를 조정할 수 있다.
- keyed message를 사용해야 한다 ▶ 파티션에 대한 향후 변경사항을 주의해야 한다.
- 이론상의 시스템에서 이벤트를 실제 예약 및 확인/청구서 이벤트에 대한 해결책은 메시지 키(학생 ID 포함)가 있는 이벤트를 실제 예약 및 확인/청구서 이벤트에 대한 2개의 토픽에 배치하는것
- 컨슈머당 메시지의 양
- 이론상의 교육 시스템에서 토픽 배치를 고려할 때 이벤트 수를 살펴봐야 한다.
- 검색 이벤트 자체는 다른 이벤트보다 많다.
- 50,000개의 검색 이벤트와 100개 미만의 예약된 교육 이벤트를 생산한다 했을때, 전체 메시지의 1%미만을 갖는 토픽을 구독하는 것에 대한 고려가 필요하다.
- 이론상의 교육 시스템에서 토픽 배치를 고려할 때 이벤트 수를 살펴봐야 한다.
- 가지고 있거나 처리해야 할 데이터의 양
- 애플리케이션에서 요구하는 제한된 시간 내에 처리하기 위해 메시지 수에 따라 여러 컨슈머에서 실행되고 있을 수 있다.
- 복수 개의 컨슈머가 설정되어 있다면 토픽의 파티션에 의해 어떻게 제한되는지 알고 있어야 한다.
- 데이터 정확성
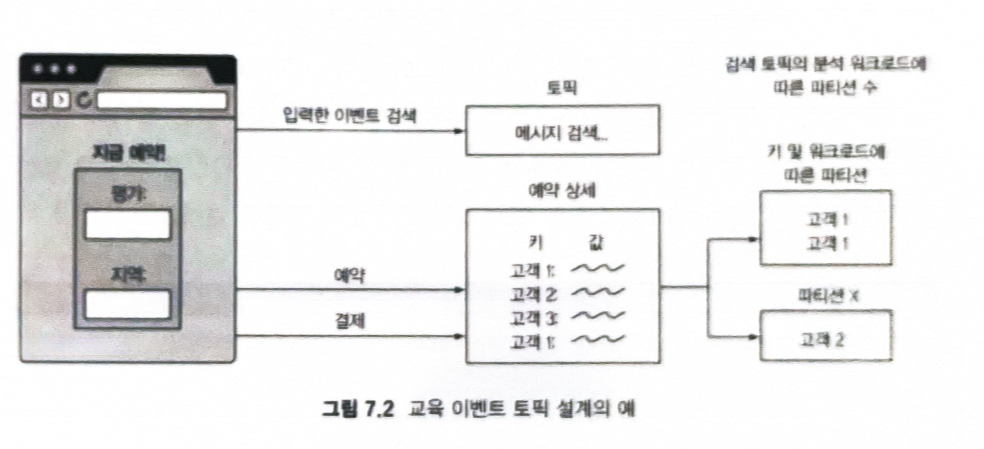
∨ 토픽에 대해 파티션 결정할 때 고려해야 할 사항은 파티션 수를 줄이는 기능이 현재 지원되지 않는다는 점이다.
- 컨슈머가 재할당된 파티션에서 읽기 시작하는 경우 파티션을 제거하면 현재 위치를 잃을 수 있다.
- 여기에서 keyed 메시지와 컨슈머 클라이언트가 브로커 수준에서 변경한 사항을 따를 수 있는지 확인해야 한다.
https://www.confluent.io/blog/how-choose-number-topics-partitions-kafka-cluster/
How to Choose the Number of Topics/Partitions in a Kafka Cluster? | Confluent
Confluent is building the foundational platform for data in motion so any organization can innovate and win in a digital-first world.
www.confluent.io
7.1.1 토픽 생성 옵션
1️⃣ 옵션 (Option)
- delete.topic.enable
- 토픽을 삭제해야 하는 지 여부를 결정한다.
- 기본값: true (Kafka 2.0 이후)
- false로 설정하면 kafka-topics.sh --delete 명령어로 토픽을 삭제할 수 없음
- auto.create.topics.enable
- 기본적으로 auto.create.topics.enable=true로 설정되어 있으며,
이 경우 생성되지 않은 토픽에 데이터를 전송하거나 소비하려 하면 자동으로 해당 토픽이 생성 - auto.create.topics.enable=false로 설정하면 자동으로 토픽이 생성되지 않는다.
- 기본적으로 auto.create.topics.enable=true로 설정되어 있으며,
2️⃣ 명령어 (Command)
- --create 매개변수로 토픽 옵션을 조회할 수 있다.
bin/kafka-topics.sh -create
- --describe 명령으로 토픽을 생성한 후에는 설정이 올바른지 확인할 수 있다.
kafka-topics.sh --bootstrap-server localhost:9092 --topic my_topic --describe
7.1.2 복제 팩터
- 실질적으로 운영되기 위해서는 총 레플리카 수가 브로커 수보다 적거나 같도록 계획해야 한다.
- 총 브로커 수보다 많은 레플리카 수로 토픽 생성하려고 하면 InvalidReplicationFactorException 오류가 발생한다.
- 2개의 브로커만 있고 3개의 파티션 레플리카가 있는 경우
- 2개의 레플리카를 호스팅하는 브로커를 잃어버리면 데이터 사본 하나만 남게 된다.
- 여러 레플리카를 잃어버리는 것은 장애 발생 시 복구를 제공하는 이상적인 방법이 아니다.
7.2 파티션
- 컨슈머 관점에서 각 파티션은 변경할 수 없는 메시지 로그다.
- 데이터를 수정하는 것이 아니라 추가하는 것으로 유지 관리한다.
- 또한 컨슈머 클라이언트는 메시지를 직접 삭제할 수 없다.
7.2.1 파티션 위치
- 로그 파일 디렉터리 조회 시
- .log인 파일은 데이터 페이로드가 저장되는 위치이다.
- .index와 .tieindex 파일을 사용해 논리적 메시지 오프셋과 인덱스 파일 내의 물리적 위치 간의 매핑을 저장한다.
ls -lh /var/lib/kafka-logs/my_topic-0total 100M
-rw-r--r-- 1 kafka kafka 50M Feb 5 12:34 00000000000000000000.log
-rw-r--r-- 1 kafka kafka 1.5M Feb 5 12:34 00000000000000000000.index
-rw-r--r-- 1 kafka kafka 500K Feb 5 12:34 00000000000000000000.timeindex
- 파티션은 많은 파일(여러 세그먼트)로 구성된다.
- 활성 세그먼트는 현재 새 메시지가 기록되고 있는 파일이다.

7.2.2 로그 보기
kinaction_topicandpart 토픽의 파티션 1에 대한 세그먼트 로그 파일 보기 위한 명령어
bin/kafka-dump-log.sh --print-data-log \
--files /tmp/kafkalinaction/kafka-logs-0/kinaction_topicandpart-1/*.log \
| awk -F: '{print $NF}' | grep kinaction
- kafka-dump-log.sh --print-data-log
- Kafka의 .log 파일을 분석하여 메시지와 메타데이터를 출력
- --files /tmp/kafkalinaction/kafka-logs-0/kinaction_topicandpart-1/*.log
- /tmp/kafkalinaction/kafka-logs-0/kinaction_topicandpart-1/ 경로의 모든 .log 파일을 대상으로 분석
- awk -F: '{print $NF}'
- 콜론(:)을 구분자로 사용하여 마지막 필드($NF, 즉 payload 부분)만 출력
- grep kinaction
- 출력된 내용 중에서 "kinaction"이라는 단어가 포함된 메시지만 필터링
offset: 0 keySize: -1 valueSize: 10 timestamp: 1712256000000 crc: 123456789 magic: 2
payload: "test_message"
offset: 1 keySize: -1 valueSize: 12 timestamp: 1712256001000 crc: 123456790 magic: 2
payload: "kinaction_test_1"
offset: 2 keySize: -1 valueSize: 15 timestamp: 1712256002000 crc: 123456791 magic: 2
payload: "kinaction_important_message"
"kinaction_test_1"
"kinaction_important_message"
7.3 EmbeddedKafkaCluster를 사용한 테스트
- Kafka Streams는 모의 객체와 본격적인 클러스터 사이의 중간 지점 역할을 하는 EmbeddedKafkaCluster라는 통합 유틸리티 클래스를 제공
package org.kafkainaction.producer;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.fail;
import java.util.List;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.streams.integration.utils.EmbeddedKafkaCluster;
import org.apache.kafka.test.TestUtils;
import org.junit.Before;
import org.junit.ClassRule;
import org.junit.Test;
import org.kafkainaction.consumer.AlertConsumer;
import org.kafkainaction.model.Alert;
import org.kafkainaction.serde.AlertKeySerde;
public class EmbeddedKafkaClusterTest {
private static final String TOPIC = "kinaction_alert";
private static final int PARTITION_NUMER = 3;
private static final int REPLICATION_NUMBER = 3;
private static final int BROKER_NUMBER = 3;
@ClassRule
public static final EmbeddedKafkaCluster embeddedKafkaCluster
= new EmbeddedKafkaCluster(BROKER_NUMBER);
private Properties kaProducerProperties;
private Properties kaConsumerProperties;
@Before
public void setUpBeforeClass() throws Exception {
embeddedKafkaCluster.createTopic(TOPIC, PARTITION_NUMER, REPLICATION_NUMBER);
kaProducerProperties = TestUtils.producerConfig(embeddedKafkaCluster.bootstrapServers(),
AlertKeySerde.class,
StringSerializer.class);
kaConsumerProperties = TestUtils.consumerConfig(embeddedKafkaCluster.bootstrapServers(),
AlertKeySerde.class,
StringDeserializer.class);
}
@Test
public void testAlertPartitioner() throws InterruptedException {
AlertProducer alertProducer = new AlertProducer();
try {
alertProducer.sendMessage(kaProducerProperties);
} catch (Exception ex) {
fail("kinaction_error EmbeddedKafkaCluster exception" + ex.getMessage());
}
AlertConsumer alertConsumer = new AlertConsumer();
ConsumerRecords<Alert, String> records = alertConsumer.getAlertMessages(kaConsumerProperties);
TopicPartition partition = new TopicPartition(TOPIC, 0);
List<ConsumerRecord<Alert, String>> results = records.records(partition);
assertEquals(0, results.get(0).partition());
}
}
7.4 토픽 컴패션
- 컴팩션의 목표는 메시지를 만료시키는 것이 아니라 키의 최신 값이 존재하는지 확인하고 이전 상태를 새 상태로 교체하는 것이다.
- 메시지의 일부인 키와 해당 키가 null이 아닌 경우에 따라 달라진다.
- 컴팩션된 토픽을 만드는데 사용한 구성 옵션은 cleanup.policy = compact 이다.
- 가장 최근의 멤버십 수준만 필요한 케이스를 살펴보자. => 컴팩션된 토픽

- 이전 세그먼트의 경우 컴팩션이 완료되면 각 키에 대한 중복값을 하나의 값으로 줄여야 한다.
- 활성 세그먼트는 아직 컴팩션을 거치지 않았다.
- 모든 메시지가 정리될 때까지 특정 키에 대한 메시지에 대해 여러 값이 존재할 수 있다.
마무리
- 토픽은 물리적인 구조라기보다는 추상적 개념이다. 토픽의 동작을 이해하려면 해당 토픽의 컨슈머는 파티션 수와 동작 중인 복제 팩터에 대해 알아야 한다.
- 파티션은 토픽을 구성하며 토픽 내 데이터의 병렬 처리를 위한 기본 단위다.
- 로그 파일 세그먼트는 파티션 디렉터리에 기록되며 브로커에서 관리된다.
- 테스트는 파티션 로직의 유효성을 검사하는 데 사용할 수 있으며 메모리 내 클러스터를 사용할 수 있다.
- 토픽 컴팩션은 특정 레코드의 최신 값 보기를 제공하는 방법이다.
반응형