반응형
6.5 카프카 모니터링(엿보기)
그라파나 Grafana와 프로메테우스 Prometheus
- 프로메테우스를 사용해 카프카의 메트릭 데이터를 추출하고 저장한다.
- 그런 다음 해당 데이터를 그라파나로 보내 그래픽 뷰를 생성한다.
카프카 익스포터 Kafka exporter
- JMX 매크릭을 받아 프로메테우스 형식으로 내보낸다.
- 프로메테우스는 이 내보낸 데이터를 수집하여 메트릭 데이터로 저장한다.
6.5.1 클러스터 유지 관리
- 프로덕션으로 구축할 때 보통 둘 이상의 서버를 구성하려고 한다.
- 카프카, 커넥트 클라이언트, 스키마 레지스트리, REST 프록시와 같은 시스템은 브로커와 동일한 서버에서 실행되지 않는다.

6.5.2 브로커 추가
- 작은 클러스터로 시작한다.
- 클러스터에 카프카 브로커를 추가하려면 고유한 ID로 새 카프카 브로커를 시작하기만 하면 된다.
- 고유한 ID로 새 카프카 브로커를 시작하기만 하면 된다.
- 이 ID는 broker.id 속성을 사용하거나 broker.id.generation.enable 속성을 true로 설정하면 된다.
- 주의할 점은, 새 브로커에 파티션이 자동으로 할당되지 않는다는 것.
- 새 브로커를 추가하기 전에 생성한 모든 토픽과 파티션은 생성 당시 존재했던 브로커에 계속 유지된다.
6.5.3 클러스터 업데이트
- 다운타임 방지하는 데 사용할 수 있는 기술은 롤링 재시작 rolling restart 이다.
- 한 번에 하나의 브로커만 업그레이드 한다.
- controlled.shutdown.enable 값을 true로 설정하면 브로커가 종료되기 전에 파티션 리더십을 이전할 수 있다.

6.5.4 클라이언트 업데이트
- 양방향 클라이언트 호환성 기능은 카프카 0.10.2의 새로운 기능이며, 브로커 버전 .10.0 이상에서 기능을 지원한다.
- 일반적으로 클러스터의 모든 카프카 브로커가 업그레이드 된 후에 클라이언트를 업그레이드 하는 것이 좋다.
6.5.5 백업
- 카프카에는 데이터베이스에 사용하는 것과 같은 백업 전략이 없다.
- MirrorMaker, Confluent Replicator, Cluster Linking
6.6 상태 저장 시스템에 대한 참고사항
- 카프카는 상태 유지 Stateful 데이터 저장소와 함께 작동하는 애플리케이션이다.
- 쿠버네티스 컨플루언트 오퍼레이터 API 와 Docker 이미지 활용해서 작업 수행할 수 있다.
- 또 다른 선택지로 스트림지 Strimzi(클라우드 네이티브 컴퓨팅 파운데이션의 샌드박스 프로젝트)이다.
Strimzi - Apache Kafka on Kubernetes
Kafka on Kubernetes in a few minutes Strimzi provides a way to run an Apache Kafka cluster on Kubernetes in various deployment configurations. Use the Quick Starts to get started now! Secure by Default Built-in security TLS, SCRAM-SHA, and OAuth authentica
strimzi.io
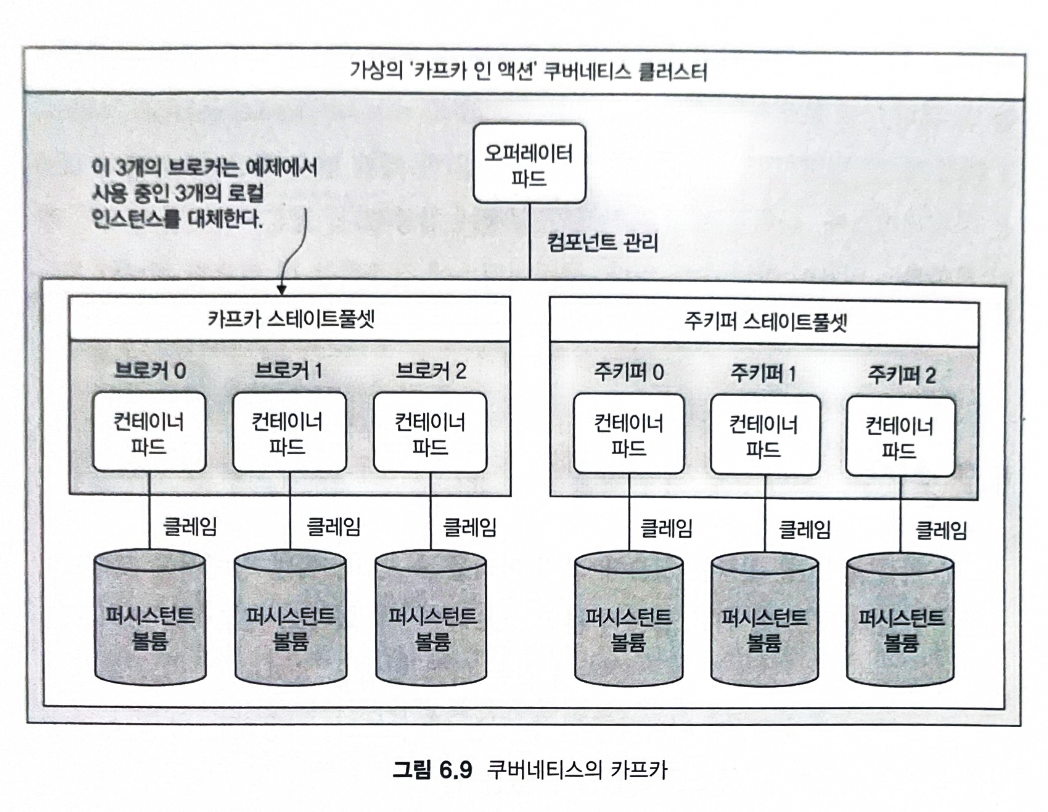
- 오퍼레이터 파드 operator pod를 사용해 쿠버네티스에서 카프카 브로커를 설정하는 방법
- 쿠버네티스 오퍼레이터는 쿠버네티스 클러스터 내부에 있는 자체 파드
- 스테이트풀셋이라는 논리 그룹의 일부로 자체 파드에 개별 브로커가 있다.
- 목적은 카프카 파드를 관리하고 각 파드에 대한 순서와 ID를 보장하는 것
- ex, ID가 0인 브로커를 호스팅 하는 파드가 실패하면 해당 ID로 새 파드가 생성되고 영구 스토리지 볼륨에 연결한다.
※ 참고로 오퍼레이터 파드 자체는 쿠버네티스 용어라고 한다.
마무리
- 브로커는 카프카의 핵심 요소이며 외부 클라이언트가 애플리케이션과 인터페이스하는 로직을 제공한다. 클러스터는 확장성뿐만 아니라 안전성도 제공한다.
- 주키퍼를 사용해 분산 클러스터에서 합의를 제공할 수 있다. 한 가지 예는 사용 가능한 여러 브로커 사이에서 새 컨트롤러를 선출하는 것이다.
- 클러스터 관리를 돕기 위해 클라이언트가 특정 옵션에 대해 브로커 수준에서 재정의할 수 있는 구성을 설정할 수 있다.
- 레플리카를 사용하면 여러 데이터 사본이 클러스터 전체에 걸쳐 있을 수 있다. 이는 브로커가 실패하고 연결할 수 없는 경우에 도움이 된다.
- 동기화 상태 레플리카는 리더의 데이터와 함께 최신 상태이며 데이터 손실 없이 파티션의 리더십을 인수받을 수 있다.
- 매트릭을 사용해 그래프를 생성하여 클러스터를 시각적으로 모니터링하거나 잠재적인 문제에 대해 경고할 수 있다.
https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
Apache Kafka - Cluster Architecture
Apache Kafka - Cluster Architecture - Take a look at the following illustration. It shows the cluster diagram of Kafka.
www.tutorialspoint.com
반응형