개요

- 컨슈머 클라이언트는 관심 있는 토픽을 구독하는 프로그램으로, 카프카에서 데이터를 가져와 다른 시스템이나 애플리케이션에 이 데이터를 제공하는 기능을 담당한다.
- 브로커 외부에 존재하는 클라이언트이므로 프로듀서 클라이언트와 마찬가지로 다양한 프로그래밍 언어로 작성 가능하다.
- 프로듀서 클라이언트와 마찬가지로 실제 컨슈머 프로세스는 별도의 시스템에서 실행할 수 있으며, 특별한 서버에서 실행할 필요는 없다.
- 실제 프로덕션 환경에서 대부분의 컨슈머 클라이언트는 별도의 호스트에 있다.
5.1 예제
- 컨슈머가 데이터가 푸쉬(push)하지 않고 토픽을 구독(pull) 하는 것을 안다는 것이 중요하다.
- 처리 제어의 권한은 컨슈머에 있는 것이다.
- 토픽에서 데이터를 읽고 애플리케이션에서 사용할 수 있도록 하거나 다른 시스템에 저장할 책임이 있다.
- 컨슈머 자신이 메시지 소비 비율을 통제한다.
- 컨슈머가 실행 도중에 실패하고 컨슈머 애플리케이션이 다시 온라인 상태가 되면 다시 메시지를 가져올 수 있다.
- 얼럿을 처리하기 위해 컨슈머를 항상 가동하고 실행할 필요가 없다.
- 데이터 흐름이 많아지거나 일정한 양으로 들어오는 데이터 때문에 생기는 역압(back pressure)을 처리하는 애플리케이션을 개발할 수 있지만, 여기서 중요한 점은 컨슈머(데이터를 소비하는 쪽)가 브로커(데이터를 관리하는 중간 역할)가 보내주는 데이터를 자동으로 듣는 방식(리스너)이 아니라, 직접 데이터를 요청해서 가져오는 방식이라는 것을 이해해야 한다는 것입니다.
- 즉, 컨슈머가 데이터를 필요로 할 때 직접 "주세요!"라고 요청해서 가져오며, 이렇게 하면 데이터를 한 번에 너무 많이 받지 않고 적절히 관리할 수 있습니다. 이는 역압을 방지하는 데 중요한 역할을 합니다.
역압(back pressure)을 처리하는 애플리케이션
역압(back pressure)을 처리하는 애플리케이션 (kafka/spark)
카프카인액션 5장을 읽다가, 아래 글을 읽으면서 찾아본 역압 back pressure의 증가를 처리하는 애플리케이션의 뜻을 찾아봤다. ...컨슈머를 항상 가동하고 실행할 필요가 없다. 이러한 일정한 데이
ddoance.tistory.com
5.1.1 컨슈머 옵션
- 메시지를 생성한 직렬 변환기와 일치하는 키와 값에 대한 역직렬 변환기를 사용하는지 확인하는 것이 중요하다.
- ex, StringSerializer를 사용해 메시지 생산했지만, LongDeSerializer를 사용해 소비하려고 하면 코드 수정이 필요한 예외가 발생한다.
- 컨슈머 작성을 시작할 때 알아야 하는 구성값
| 키 | 용도 |
| bootstrap.servers | 시작할 때 연결할 하나 이상의 카프카 브로커 |
| value.deserializer | 값 역직렬화에 필요 |
| key.deserializer | 키 역직렬화에 필요 |
| group.id | 컨슈머 그룹에 조인하기 위해 사용되는 ID |
| client.id | 유저를 식별하기 위한 ID |
| heartbeat.interval.ms | 컨슈머가 그룹 코디네이터에게 핑(ping) 신호를 보낼 간격 |
https://kafka.apache.org/27/javadoc/org/apache/kafka/clients/consumer/ConsumerConfig.html
ConsumerConfig (kafka 2.7.0 API)
kafka.apache.org
- 소스코드 예시
Kafka-In-Action-Source-Code/KafkaInAction_Chapter5/src/main/java/org/kafkainaction/consumer/WebClickConsumer.java at master · K
Source Code for the book Kafka in Action. Contribute to Kafka-In-Action-Book/Kafka-In-Action-Source-Code development by creating an account on GitHub.
github.com
package org.kafkainaction.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.List;
public class WebClickConsumer {
final static Logger log = LoggerFactory.getLogger(WebClickConsumer.class);
private volatile boolean keepConsuming = true;
public static void main(String[] args) {
Properties kaProperties = new Properties();
kaProperties.put("bootstrap.servers",
"localhost:9092,localhost:9093,,localhost:9094");
kaProperties.put("group.id", "kinaction_webconsumer"); //<1>
kaProperties.put("enable.auto.commit", "true");
kaProperties.put("auto.commit.interval.ms", "1000");
kaProperties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer"); //<2>
kaProperties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
WebClickConsumer webClickConsumer = new WebClickConsumer();
webClickConsumer.consume(kaProperties);
Runtime.getRuntime().addShutdownHook(new Thread(webClickConsumer::shutdown));
}
private void consume(Properties kaProperties) {
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(kaProperties)) { //<3>
consumer.subscribe(List.of("kinaction_promos")); //<4>
while (keepConsuming) { //<5>
var records = consumer.poll(Duration.ofMillis(250));
for (ConsumerRecord<String, String> record : records) {
log.info("kinaction_info offset = {}, key = {}",
record.offset(), record.key());
log.info("kinaction_info value = {}", Double.parseDouble(record.value()) * 1.543);
}
}
}
}
private void shutdown() {
keepConsuming = false;
}
}▶ 왜 루프를 사용할까 ? 이벤트가 연속적인 스트림으로 포함될 것이므로 사용해야 한다.
▶ 만약 모든 메시지에 대해서 값 소비한 후 다시 데이터를 처음부터 쌓아야하는 케이스가 있다면 메시지 리플레이를 통해 다시 한 번 처리하면 된다.
5.1.2 코디네이트 이해
1) 오프셋 offset
- 컨슈머가 브로커에게 보내는 로그의 인덱스 위치로 오프셋을 사용한다.
- 이를 통해 로그는 소비하려는 메시지 위치를 알 수 있다.
2) auto.offset.reset 매개변수
| 옵션 | 읽기 시작 위치 | 사용 사례 | 주의점 |
| latest | 가장 최근 메시지부터 | 실시간 데이터 스트림 처리 | 과거 메시지는 무시된다. |
| earliest | 토픽의 처음 메시지부터 | 과거 데이터 분석, 처음부터 처리해야 할 때 | 오래된 데이터 처리 시간 증가 |
위의 내용을 기반으로 애플리케이션의 데이터 처리 목적에 따라 적절한 옵션을 선택하면 된다.
- --from-beginning 플래그를 사용하면 컨슈머 auto.offset.reset 매개변수를 earliest로 설정한다.
- 해당 구성을 사용하면 콘솔 컨슈머를 시작하기 전에 전송된 경우에도 연결된 파티션의 해당 토픽에 대한 모든 레코드를 볼 수 있다.
- -auto.offset.reset 매개변수 기본값은 latest이다.
- 이 옵션은 컨슈머가 읽고 있는 토픽 파티션에 이미 있는 메시지 처리를 무시한다.
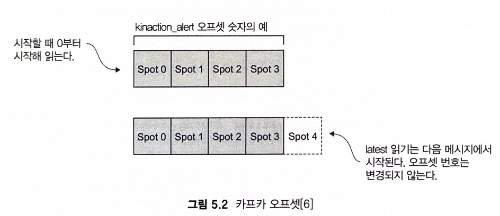
3) 오프셋은 항상 각 파티션에 대해 증가한다.
- 토픽 파티션에 오프셋 0이 표시되면 나중에 해당 메시지가 제거되더라도 오프셋 번호는 다시 사용되지 않는다.
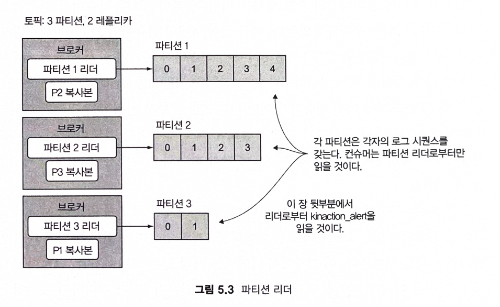
- 컨슈머는 일반적으로 컨슈머의 파티션 리더 레플리카에서 읽는다.
- 또한 파티션에 대해 이야기할 때 파티션 간에 오프셋 번호가 같아도 괜찮다. 메시지를 구분하는 기능에는 오프셋뿐만 아니라 토픽 내에서 어떤 파티션을 처리하고 있는지에 대한 세부 정보가 포함돼야 한다.
4) 각 컨슈머 그룹에 대해 특정 브로커가 그룹 코디네이터 역할을 수행한다.
- 컨슈머 클라이언트는 메시지를 읽기 위해 필요한 다른 세부 정보와 함께 파티션 할당 정보를 얻기 위해 이 코디네이터와 대화한다.
5) 메시지 소비는 파티션의 수도 영항을 미친다.
- 파티션보다 컨슈머가 많으면 일부 컨슈머는 작업을 수행하지 않는다.
- 어떤 경우에는 컨슈머가 예기치 않게 실패한 경우에도 비슷한 비율의 소비가 발생하도록 해야 할 수 있다.
- 그룹 코디네이터는 그룹 시작 초기에 어떤 컨슈머가 어떤 파티션을 읽을지 지정하는 것 뿐만 아니라 컨슈머가 추가되거나 실패하여 그룹을 종료할 때도 컨슈머를 할당한다.
- 컨슈머보다 파티션이 더 많은 경우 필요에 따라 하나의 컨슈머가 둘 이상의 파티션을 처리한다.
6) 리더 레플리카 3개, 4개의 컨슈머 예시

7) 파티션 수를 항상 최대치로 사용하지 않는 이유
- 브로커 간에 파티션이 복제될 때까지 기다려야 하기 때문에 종단 간 대기 시간을 증가시킬 수 있다.
- 또한 컨슈머에 대한 파티션의 1:1매핑이 아닌 경우 더 많은 파티션이 할당됨에 따라 각 컨슈머의 메모리 요구가 증가될 수 있음.
5.2 컨슈머가 상호 작용하는 방식
- 컨슈머 그룹이 중요한 이유 ? 그룹에 컨슈머를 추가하거나 그룹에서 제거함으로써 처리 규모에 영향을 준다.
- 새 그룹 id가 필요한지 여부를 결정하는데 있어서 중요한 세부 사항은 컨슈머가 하나의 애플리케이션의 일부로 작업하는지 아니면 별도의 논리 흐름으로 작업 하는지이다.
- ex, 인사 시스템에서 가져온 데이터 중 한 팀은 특정 주 state의 고용 수에 대해 궁금해하고, 다른 팀은 인터뷰를 위한 여행 예산에 미치는 영향에 대한 데이터를 궁금할 수 있다.
- 다른 컨슈머와 동일한 group.id를 사용하는 각 컨슈머는 해당 토픽의 파티션과 오프셋을 하나의 논리적 애플리케이션으로 소비하기 위해 함께 작업하는 것으로 간주
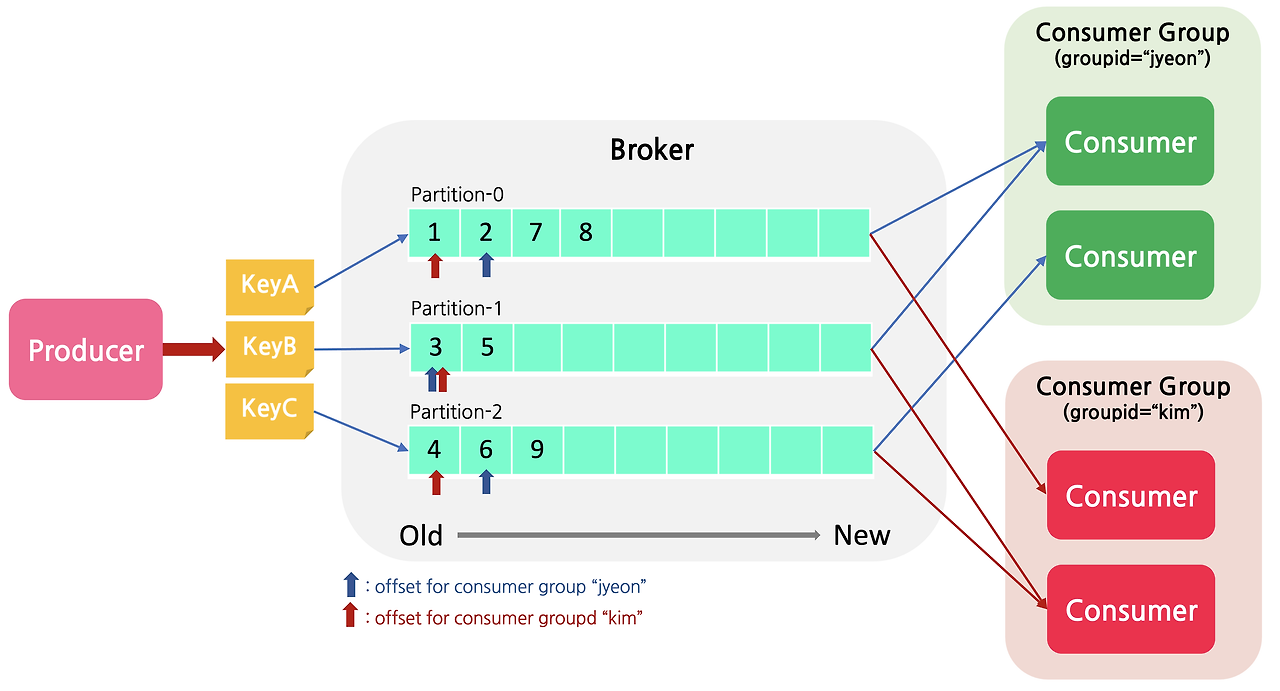
Apache Kafka 기본 개념 (Partition / Consumer / Consumer Group/ Offset Management)
https://jyeonth.tistory.com/30