5.3 추적
다른 시스템에서 일부 메시지 브로커가 메시지를 처리하는 방법
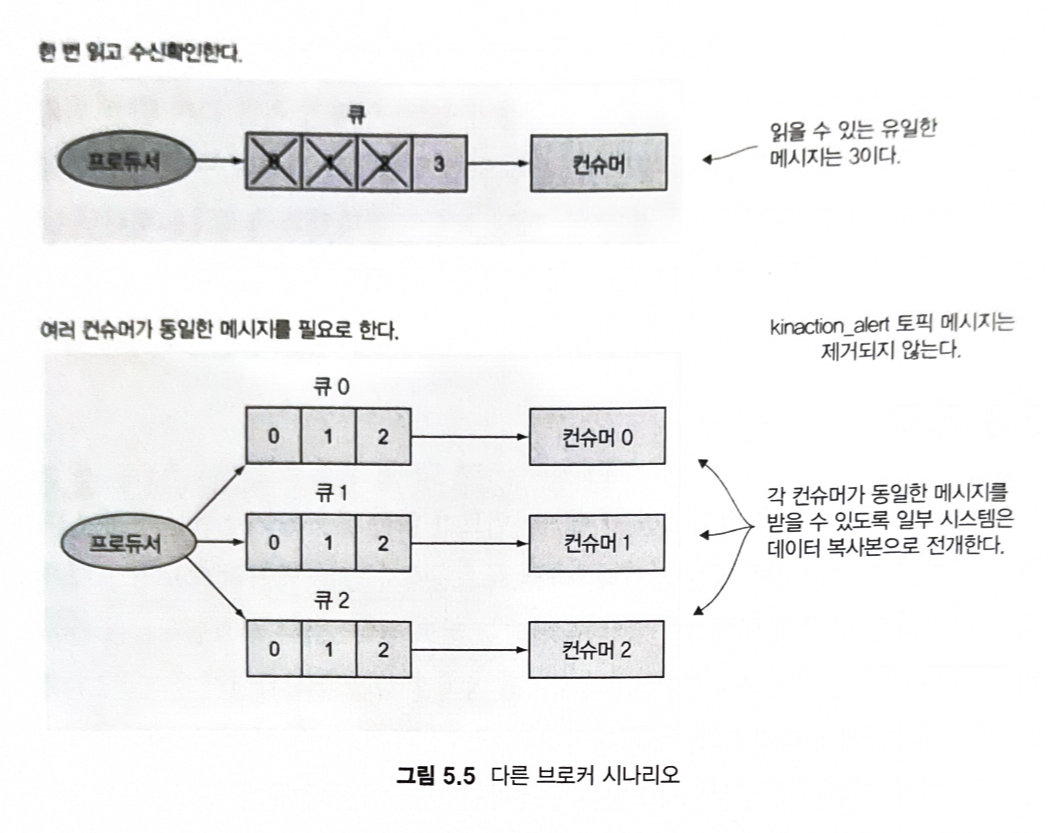
1) 일부 시스템에서는 컨슈머가 읽은 내용을 기록하지 않는다.
- 메시지를 가져온 다음 수신확인한 후에 그 메시지는 대기열에서 사라진다.
- 하나의 애플리케이션이(컨슈머) 하는 단일 메시지에 적합
2) 구독자인 모든 사람에게 메시지를 게시한다.
- 미래의 구독자는 이벤트 발생했을때 수신자 목록에 없기 때문에 놓친다.
5.3.1 그룹 코디네이터
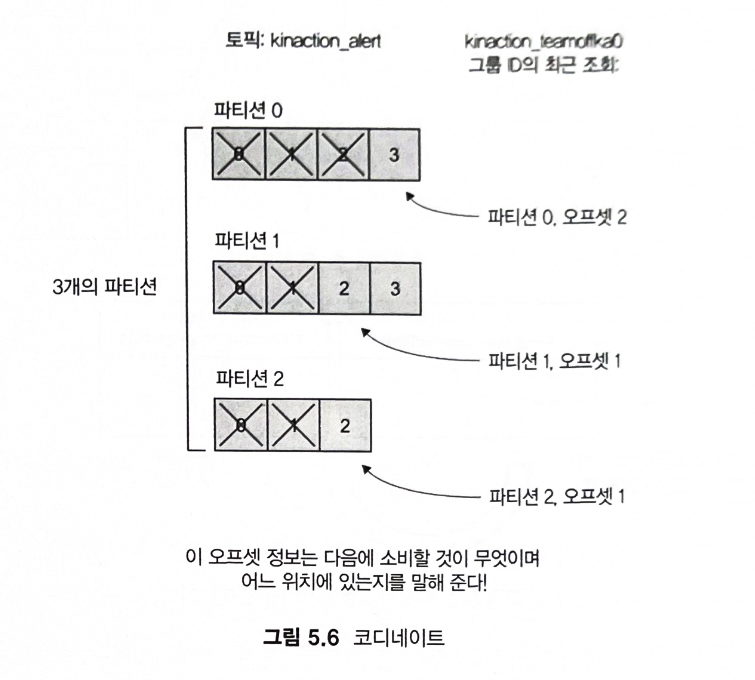
- 토픽에서 다음 메시지를 읽을 위치 결정하기 위해 오프셋 커밋을 좌표로 사용한다.
- 예를 들어, 파티션0이 할당된 컨슈머는 다음 오프셋 3을 읽을 준비가 된다.
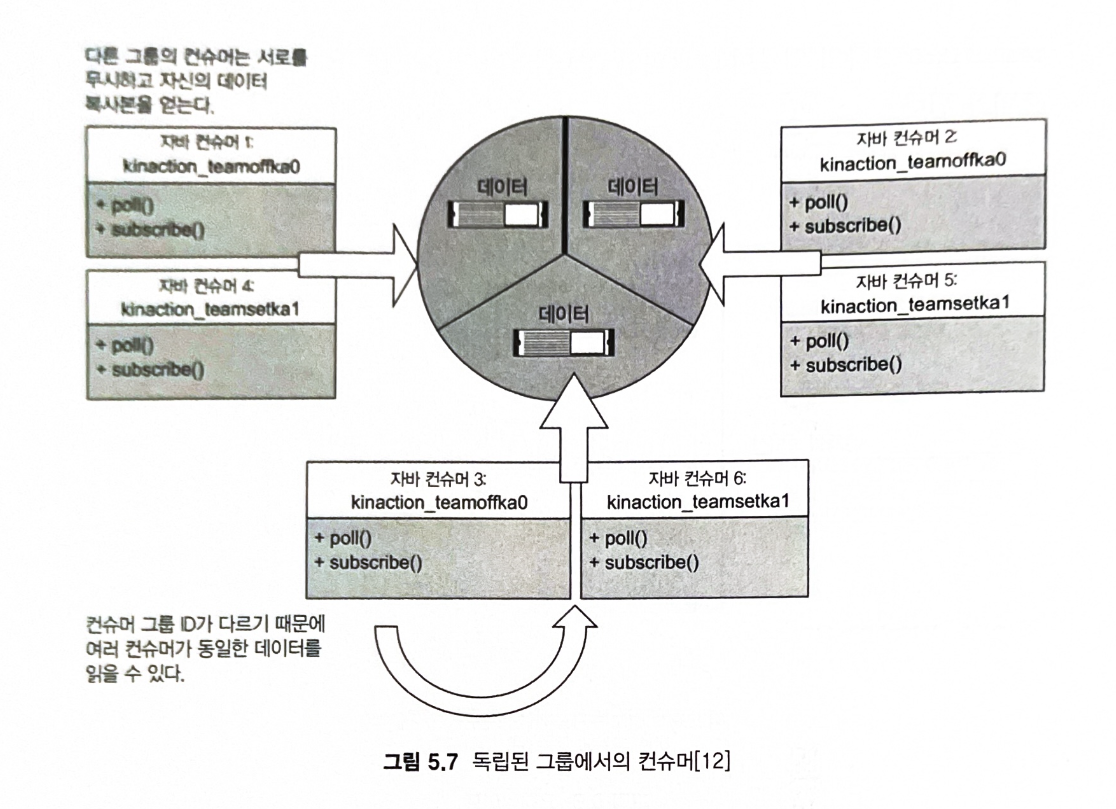
- 동일한 파티션 집합이 3개의 각기 다른 브로커에 존재하며, kinaction_teamoffka0과 kinaction_teamsetka1이라는 2개의 컨슈머 그룹이 파티션에서 메시지 소비한다.
- 각 그룹의 컨슈머는 각 브로커의 파티션에서 고유한 데이터 복사본을 가져온다.
- 같은 그룹의 일부가 아니면 함께 작동하지 않는다.
=> 일반적으로 컨슈머 그룹당 하나의 컨슈머만 하나의 파티션을 읽을 수 있다. 즉, 파티션은 많은 컨슈머가 읽을 수 있지만, 한 번에 각 그룹의 한 컨슈머만 읽을 수 있다.
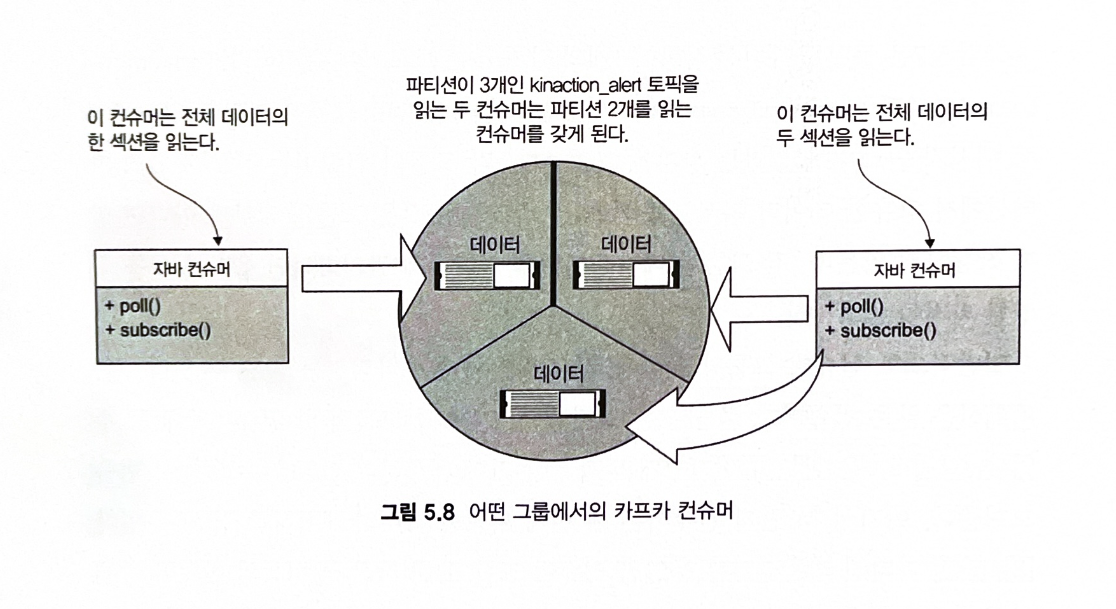
- 한 컨슈머가 2개의 파티션 리더 레플리카를 읽을 수 있다.
- 두번째 컨슈머는 세 번째 파티션 리더의 데이터만 읽을 수 있다.
- 단일 파티션 레플리카는 동일한 컨슈머 그룹 ID를 가진 둘 이상의 컨슈머 간에 분할되거나 공유되지 않는다.
5.3.2 파티션 할당 전략
partition.assignment.strategy 전략 : range, roundrobin, sticky (버전 0.11.0에 추가), cooperativesticky
1) 레인지 할당자 range assigner
- 단일 토픽을 사용해 파티션 수(번호순)를 찾은 다음 컨슈머 수로 분할한다.
- 분할이 짝수가 아닌 경우 첫번째 컨슈머는 남은 파티션을 가져온다.
- 처리할 파티션에 컨슈머가 골고루 분산되어 있는지 환인하고 일부 컨슈머 클라이언트가 대부분 리소스 사용하면 다른 할당 전략으로 교체한다.
2) 라운드 로빈 round-robin
- 파티션이 컨슈머 밑으로 균일하게 분산되는 방식
- 첫번째 컨슈머는 첫번째 파티션을, 두번째 컨슈머는 두 번째 파티션을 가져오는 식으로 파티션이 모두 소진될 때까지 계속

5.4 작업 위치 표시 enable.auto.commit
애플리케이션이 토픽의 모든 메시지를 읽도록 해야 한다는 것은 고려해야할 중요한 사항 중 하나이다. 몇 개를 놓쳐도 괜찮은가 ? 아니면 각 메시지를 읽었음을 확인해야 하는가 ? 각 메시지를 좀 더 안전하게 조회하기 위해 속도를 약간 희생해도 괜찮은가 ?
1) enable.auto.commit = true
- 컨슈머 클라이언트의 기본값.
- 오프셋은 컨슈머 클라리언트가 대신 커밋해 준다.
- 소비되는 오프셋을 커밋하기 위해 다른 호출을 할 필요가 없다.
- 장점:
- 설정이 간단하며, 컨슈머가 추가적인 코드 없이 오프셋을 관리할 수 있다.
- 애플리케이션이 중단되더라도 재시작 시 자동으로 마지막 커밋된 위치부터 읽기 시작한다.
- 단점:
- 메시지 손실 위험: 메시지가 성공적으로 처리되기 전에 커밋되면, 애플리케이션이 중단되었을 때 해당 메시지가 손실될 가능성이 있다.
- 중복 처리 위험: 커밋 주기 전에 애플리케이션이 중단되면, 이미 처리한 메시지가 다시 처리될 수 있다.
2) enable.auto.commit = false
- 최소 한 번 배달을 보장할 수 있다.
- 애플리케이션이 실제로 메시지를 사용하고 커밋할 때 대부분의 관리를 직접 수행할 수 있다.
- 수동 커밋은 다음 메서드를 사용하여 구현한다:
- commitSync(): 동기적으로 커밋.
- commitAsync(): 비동기적으로 커밋.
- 장점:
- 메시지가 성공적으로 처리된 후에만 커밋할 수 있어 데이터 처리의 정확성을 보장한다.
- 실패 시에도 중복 메시지 처리를 최소화할 수 있다.
| 옵션 | 징잠 | 딘잠 |
| enable.auto.commit=true | 간단한 설정, 기본 동작 | 메시지 손실 또는 중복 처리 가능성 |
| enable.auto.commit=false | 처리 완료 후 커밋 가능, 데이터 처리 정확성 보장 | 추가적인 구현 필요, 복잡도 증가 |
enable.auto.commit=true는 간단한 작업에는 유용하지만, 데이터의 신뢰성이 중요한 경우 수동 커밋을 사용하는 것이 더 적합하다.
5.5 컴팩션된 토픽에서 읽기
- 컨슈머는 컴팩션된 토픽을 일고 있다.
- 카프카는 백그라운드 프로세스에서 파티션 로그를 컴팩션하고, 마지막 키를 제외하고 동일한 키를 가진 레코드가 제거될 수 있다.
- 컨슈머에게 오류를 일으킬 수 있는 가장 큰 '문제'는 컴팩션된 토픽에서 레코드를 읽을 때 컨슈머가 단일 키에 대해 여러 항목을 읽을 수 있다는 점이다.
- 디스크에 있는 로그 파일에서 실행되기 때문에 클린업 동안 메모리에 있는 메시지를 보지 못할 수 있다.
- 결국 클라이언트는 같은 키에 둘 이상의 값이 있는 이 경우를 처리해야 한다.
- 중복 키를 처리하고 필요한 경우 마지막 값을 제외한 모든 값을 무시하는 로직이 있어야 한다.
5.6 우리 공장의 요구사항에 대한 코드 검색
5.6.1 읽기 옵션
- 카프카의 키에 의한 메시지 조회 옵션은 없지만, 특정 오프셋을 찾는 것은 가능하다.
- 메시지 로그가 인덱스가 있는 각 메시지와 함께 계속 증가하는 배열이라고 생각하면 처음부터 시작하기, 마지막으로 이동하기 또는 특정 시간을 기반으로 오프셋 찾기를 포함해 몇 가지 옵션이 있음
- 처음부터 시작하기 (earliest)
- ex, 이미 읽었더라도 토픽의 시작 부분부터 읽고 싶은 경우 : 로직 오류, 전체 로그의 리플레이, 카프카 시작한 후 데이터 파이프라인의 오류
- auto.offset.reset를 earliest로 설정하거나 다른 컨슈머 그룹 ID를 사용하면 된다.
- 마지막으로 이동하기 (latest)
- 과거 메시지 제외하고 로직 시작하고 싶을 때
- 특정 시간을 기반으로 오프셋 찾기 (offsetForTimes)
- ex, 기록된 이벤트와 관련된 예외가 발생한 경우 컨슈머를 사용해 특정 타임스탬프 부근에 처리된 데이터 확인할 수 있음
- 처음부터 시작하기 (earliest)
5.6.2 요구사항
3.2.4장의 감사 데이터 예시
[카프카인액션] 3장. 카프카 커넥트 | 카프카 소스 커넥터 | 카프카 소스 + 싱크 커넥터 | 카프카
3.1 카프카 프로젝트 설계 3.1.1 기존 데이터 아키텍쳐 인수- 새로운 가상의 컨설팅 회사는 원격으로 전기 자전거를 관리하는 공장을 재설계하는 계약을 막 따냈다. - 센서는 모니터링하는 내부
ddoance.tistory.com
감사 데이터
- 규정 준수를 위해 센서 자체에 대해 누가 어떤 관리 작업을 수행하는지 알고 싶다.
- 우리의 주요 관심사는 처리할 모든 데이터가 있는지다. 순서는 중요하지 않다.
- 각 감사 이벤트에 대해 로직이 실행되도록 하는 안전한 방법은 소비된 직후 레코드별 오프셋을 구체적으로 커밋하는 것 (enable.auto.commit = false)
kaProperties.put("enable.auto.commit", "false");Kafka-In-Action-Source-Code/KafkaInAction_Chapter5/src/main/java/org/kafkainaction/consumer/AuditConsumer.java at master · Kafk
Source Code for the book Kafka in Action. Contribute to Kafka-In-Action-Book/Kafka-In-Action-Source-Code development by creating an account on GitHub.
github.com
- commitSync 메서드가 호출되고 방금 처리된 레코드의 오프셋이 포함된 오프셋 맵이 전달된다.
private void consume(final Properties kaProperties) {
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(kaProperties)) {
consumer.subscribe(List.of("kinaction_audit"));
while (keepConsuming) {
var records = consumer.poll(Duration.ofMillis(250));
for (ConsumerRecord<String, String> record : records) {
log.info("kinaction_info offset = {}, value = {}",
record.offset(), record.value());
OffsetAndMetadata offsetMeta = new OffsetAndMetadata(record.offset() + 1, "");
Map<TopicPartition, OffsetAndMetadata> kaOffsetMap = new HashMap<>();
kaOffsetMap.put(new TopicPartition("kinaction_audit", record.partition()), offsetMeta);
consumer.commitSync(kaOffsetMap);
}
}
}
}
5장 요약
- 컨슈머 클라이언트는 개발자에게 카프카에서 데이터를 가져오는 방법을 제공한다. 프로듀서 클라이언트와 마찬가지로 컨슈머 클라이언트에는 커스텀 코딩을 사용하는 대신, 설정할 수 있는 많은 구성 옵션이 있다.
- 컨슈머 그룹을 사용하면 둘 이상의 클라이언트가 그룹으로 작업하여 레코드를 사용할 수 있다. 이 그룹화를 통해 클라이언트는 데이터를 병렬로 처리할 수 있다.
- 오프셋은 브로커에 존재하는 커밋 로그의 레코드 위치를 나타낸다. 컨슈머는 오프셋을 사용해 데이터 읽기를 시작할 위치를 제어할 수 있다.
- 오프셋은 컨슈머가 이미 본 적이 있는 기존 오프셋이 될 수도 있으며, 레코드를 리플레이할 수도 있다.
- 컨슈머는 동기 또는 비동기 방식으로 데이터를 읽을 수 있다.
- 비동기 메서드를 사용한다면 데이터가 수신될 때 컨슈머는 콜백 코드에 실행할 로직을 사용할 수 있다.