반응형
Chapter4. 기존 시스템에 이벤트 기반 아키텍쳐 통합
4.1 데이터 해방이란 ? data liberation
- 데이터 해방은 교차 도메인 데이터 세트를 식별해서 각 이벤트 스트림에 발행하는 이벤트 기반 아키텍쳐 마이그레이션 전략의 일부분이다.
- 교차 도메인 데이터 세트(cross-domain data set)를 식별하여 각 이벤트 스트림에 발행하는 이벤트 기반 아키텍처의 마이그레이션 전략이다.
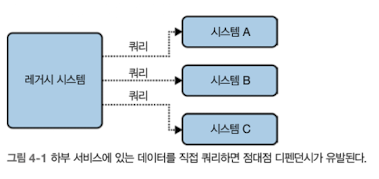

MSA 마이그레이션 : 데이터 해방
모놀리식 기반의 레거시 시스템을 이벤트 기반 아키텍처로 전환하는 것은 여러 기업이 성장하면서 새로운 비즈니스 요건을 충족해야 하거나 규모를 늘릴 때 많이 거쳐가는 단계이다. 오늘은
ddonghyeo.tistory.com
4.1.1 데이터 해방 시 고려사항
- 데이터 세트와 해방된 이벤트 스트림은 완전히 동기화돼야 한다.
- 새 마이크로서비스와 리펙터링한 레거시 애플리케이션에서 모두 이벤트 브로커에 상태를 유지하는게 이상적이지만 모든 애플리케이션에서 그렇게까지 할 필요는 없다.
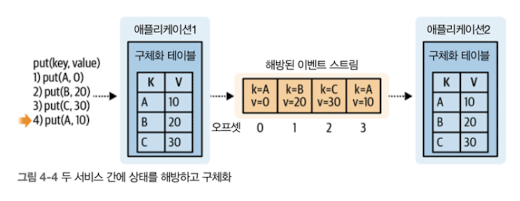
4.2 데이터 해방 패턴
- 세 가지 패턴의 공통점은 소스 레코드의 최근 업데이트 시간 컬럼을 이용해 이벤트를 타임 스템프로 생산해야 한다는 점이다.
- 프로듀서가 이벤트를 발행한 시간이 아닌, 이벤트 자체가 발생한 시간이 타임스탬프로 찍힌 이벤트 스트림이 생성된다.
1) 쿼리 기반 query-based
- 하부 데이터 저장소를 쿼리해서 데이터를 추출한다.
- 어떤 종류의 데이터 저장소든 작업이 가능하다.
2) 로그 기반 log-based
- 하부 데이터 구조의 변경 내역을 기록한 붙임 전용 로그를 기준으로 데이터를 추출한다.
- 데이터 변경 로그를 보관하는 데이터 저장소에서만 가능한 방법이다.
3) 테이블 기반 table-based
- 출력 큐로 사용할 테이블에 데이터를 푸시한다.
- 다른 스레드나 별도의 프로세스가 테이블을 쿼리해 데이터를 정해진 이벤트 스트림으로 내보낸 뒤 관련 엔트리를 삭제한다.
4.3 데이터 해방 프레임워크
- 데이터를 이벤트 스트림으로 추출하는 카프카 커넥트, 아파치 고블린, 아파치 나이파이 같은 중앙화 프레임워크를 사용하면 된다.
- 이런 프레임워크 사용하면 하부 데이터 세트 쿼리한 결과를 출력 이벤트 스트림에 흘릴 수 있고 필요 시 인스턴스를 더 추가해서 CDC 작업 용량을 늘릴 수 있다.
4.4. 쿼리로 데이터 해방
- 데이터 저장소를 쿼리한 결과를 관련 이벤트 스트림에 흘려보낸다.
- 클라이언트는 API, SQL 또는 유사 SQL 언어 이용해 데이터 저장소에서 원하는 데이터 세트를 요청한다.
- 데이터 세트는 최초 1회 벌크 쿼리한 다음 주기적으로 업데이트 해서 변경분을 출력 이벤트 스트림에 생산한다.
4.4.1 벌크 로딩
- 벌크 쿼리를 실행해서 전체 데이터를 로드한다.
- 전체 데이터를 가져오기 때문에 비용이 많이 든다.
4.4.2 증분 타임스탬프 로딩
- 이전 쿼리 결과의 최종 타임스탬프 이후에 쌓인 데이터를 쿼리해서 적재한다.
- 최근 업데이트 시간(updated_at) 컬럼/필드 기준으로 레코드가 가장 마지막에 수정된 시간 찾아 매번 증분 업데이트 할때 마다 최종 수정시간 컬럼/필드가 이 시간 이후인 레코드만 가져온다.
4.4.3 자동증가 ID 로딩
- 증분 업데이트를 할 때마다 ID 값이 마지막으로 처리한 ID보다 큰 데이터만 쿼리해서 적재한다.
- 선후 관계가 분명한 자동증가 정수 또는 Long 타입 필드가 필요하다.
4.4.4 맞춤 쿼리
- 맞춤 쿼리 custom query로 제한해 대용량 데이터 중 일부만 필요하거나 내부 데이터 모델이 과도하게 노출되는 것을 막기 위해 여러 테이블을 조인하고 반정규화 할때 사용한다.
4.4.5 증분 업데이트
- 증분 업데이트를 하려면 먼저 데이터 세트의 레코드에 필요한 타임스탬프나 자동 증가 ID가 있어야 한다.
- 다음으로, 폴링 빈도와 업데이트 지연 시간을 정해야 한다.
- 업데이트 자주 하면 다운스트림 데이터를 업데이트하는 지연이 줄어드는 반면, 데이터 저장소에 걸리는 총 부하량이 늘어난다.
- 앞 쿼리가 아직 로드 중인데 쿼리를 또 시작하면 옛 데이터가 출력 이벤트 스트림의 새 데이터를 덮어 쓰는 경합 조건이 발생한다.
- 증분 업데이트 필드와 빈도가 결정되면 마지막으로 벌크 로드를 1회 수행해야 한다.
| 장점 | 단점 |
|
|
4.5. CDC 로그로 데이터 해방
- CDC 로그 (예: MySQL 바이너리 로그, PostgreSQL 선행 기입 로그)를 활용하는 방법으로 시간 경과에 따라 데이터 세트에 발생하는 모든 일을 붙임 전용 로그 형태로 남긴 것이다.
- 모든 데이터 저장소가 제공하는 기능이 아니기 때문에 기술 선택의 폭은 매우 좁다.
- MySQL, PostgreSQL 등 몇몇 RDB에서 가능하고, 최신 데이터 저장소 대부분은 물리적 로그 선행 기입(WAL)의 프록시 역할 하는 이벤트 API를 제공하기도 한다.
- 데이터 저장소 로그는 용량이 매우 커질 가능성이 높고 따로 장기 보관할 필요는 없기 때문에 처음부터 발생한 변경 기록을 전부 포함하고 있지 않다.
- 데이터 저장소 로그에서 CDC 프로세스를 시작하기 전에 기존 데이터의 스냅샷을 찍어야한다.
- 부트 스트래핑 bootstrapping 이라고 불리는 작업이고 대개 성능에 영향을 미칠 정도의 대용량 쿼리가 수반된다.
- 체인지로그 changelog 변경분 로그에서 데이터를 소싱할 때 가장 널리 쓰이는 방법은 데베지움 이다.

상품데이터 Pipeline을 위한 Debezium MSK Connect | 올리브영 테크블로그
MSK Connect Oracle / Aurora CDC
oliveyoung.tech
| 장점 | 단점 |
|
|
4.6 아웃박스 테이블로 데이터 해방
- CDC 대상으로 표시된 데이터 저장소에서 테이블 레코드가 사입, 수정, 삭제될 때마다 해당 레코드가 아웃박스 테이블에 발행되는 구조
- 내부 테이블의 업데이트와 아웃박스 테이블의 업데이트는 단일 트랜잭션으로 묶어 트랜잭션 성공 시에만 두 업데이트가 일어나게 된다.

| 장점 | 단점 |
|
|
cf) 트리거 사용하면 좋은점/나쁜점
| 장점 | 단점 |
|
|
반응형
'스터디' 카테고리의 다른 글
| [이벤트 기반 마이크로서비스 구축] Chapter9 FaaS 응용 마이크로서비스 (0) | 2026.02.21 |
|---|---|
| [이벤트 기반 마이크로서비스 구축] Chapter8 마이크로서비스 워크플로 구축 - 미쉐린은 오케스트레이션을 버렸고, Netflix는 오케스트레이션을 만들었다 (0) | 2026.02.20 |
| [이벤트 기반 마이크로서비스 구축] Chapter1. 왜 이벤트 기반 마이크로서비스인가? (1) | 2026.01.04 |
| Chapter5(2). 네트워크 - 4 전송 계층 - TCP와 UDP | 5 응용 계층 - HTTP의 기초 (0) | 2025.12.07 |
| Chapter5(1). 네트워크 (1) | 2025.11.30 |