Kafka Connect High-Level Overview

- 1 Kafka Connector Source (클러스터에서 실행됨)는 외부 소스에서 데이터를 가져옵니다.
- 2 Kafka Connector Source는 수집된 데이터를 Kafka 클러스터로 전송합니다 (이 단계에서 프로듀서 역할을 수행).
3a. Kafka 클라이언트 애플리케이션(소비자로 작동)이 Kafka 클러스터에서 데이터를 읽습니다.
3b. Kafka 클라이언트 애플리케이션(이제 프로듀서로 작동)이 처리된 데이터를 Kafka 클러스터로 다시 보냅니다. - 4 Kafka Connector Sink (클러스터에서 실행됨)는 Kafka 클러스터에서 데이터를 읽습니다 (이 단계에서 소비자 역할을 수행).
- 5 Kafka Connector Sink는 읽은 데이터를 외부 싱크로 전송합니다.
Cluster and Distributed Architecture
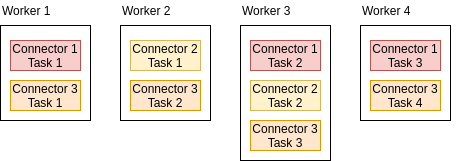
Kafka Connect는 독립 실행형 또는 분산 모드로 실행할 수 있습니다.
| 특징 | Standalone Worker | Distributed Worker |
| 구성 방식 | 하나의 프로세스가 커넥터와 태스크를 모두 실행 | 여러 워커가 커넥터와 태스크를 분산 실행 |
| 설정 방법 | .properties 파일 사용 | REST API를 통해 설정 |
| 사용 용이성 | 사용이 매우 간단하며, 개발 및 테스트 환경에 적합 | 운영 환경에 적합 |
| 장애 내성 및 확장성 | 장애 내성 없음, 확장성 부족, 모니터링 어려움 | 확장 용이 (새 워커 추가만으로 가능), 장애 내성 (비활성 워커 발생 시 자동 리밸런싱) |
독립 실행형 모드
독립 실행형 모드에서 Kafka Connect를 구성하려면 config/connect-standalone.properties 구성 파일을 편집합니다. 다음 옵션이 가장 중요합니다.
분산 모드
https://www.youtube.com/watch?v=52HXoxthRs0
독립 실행형 모드 vs 분산 모드
http://www.igfasouza.com/blog/kafka-connector-architecture/
kafka Connector Architecture – Igfasouza.com
What’s the story Rory? This blog post is part of my series of posts regarding “Kafka Connect Overview“. If you’re not familiar with Kafka, I suggest you have a look at my previous post “What is Kafka?” before. This post is a collection of links
www.igfasouza.com
kafka connect cluster, kafka cluster
https://daniel.arneam.com/blog/distributedarchitecture/2020-10-15-Kafka-Connect-Concepts/
Kafka Connect Concepts
Review of the connect concepts in Apache Kafka.
daniel.arneam.com
독립 실행형 모드 vs 분산 모드
7장. Kafka Connect | Red Hat Product Documentation
형식멀티 페이지단일 페이지모든 문서를 PDF로 표시
docs.redhat.com
'개발 > kafka' 카테고리의 다른 글
| [kafka] 소비자 그룹 (Consumer Group) (1) | 2025.01.05 |
|---|---|
| [kafka] log compaction | log tail | log head (1) | 2025.01.04 |
| [kafka] producer message key = 메시지 코디네이트(Message Coordinate) (1) | 2025.01.04 |
| [kafka] 토픽 생성 및 리스트 확인 + producer, consumer 메시지 전달 (mac m1) (0) | 2024.12.14 |
| [kafka] kafka, zookeeper, server 시작하기 (mac m1) (0) | 2024.12.14 |